
Page 284 - Ai Book - 10
P. 284
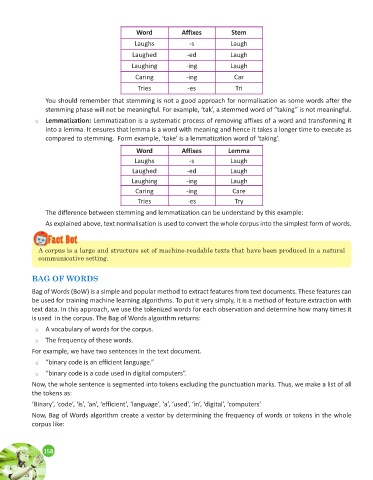
Word Affixes Stem
Laughs -s Laugh
Laughed -ed Laugh
Laughing -ing Laugh
Caring -ing Car
Tries -es Tri
You should remember that stemming is not a good approach for normalisation as some words after the
stemming phase will not be meaningful. For example, ‘tak’, a stemmed word of “taking” is not meaningful.
u Lemmatization: Lemmatization is a systematic process of removing affixes of a word and transforming it
into a lemma. It ensures that lemma is a word with meaning and hence it takes a longer time to execute as
compared to stemming. Form example, ‘take’ is a lemmatization word of ‘taking’.
Word Affixes Lemma
Laughs -s Laugh
Laughed -ed Laugh
Laughing -ing Laugh
Caring -ing Care
Tries -es Try
The difference between stemming and lemmatization can be understand by this example:
As explained above, text normalisation is used to convert the whole corpus into the simplest form of words.
A corpus is a large and structure set of machine-readable texts that have been produced in a natural
communicative setting.
BAG OF WORDS
Bag of Words (BoW) is a simple and popular method to extract features from text documents. These features can
be used for training machine learning algorithms. To put it very simply, it is a method of feature extraction with
text data. In this approach, we use the tokenized words for each observation and determine how many times it
is used in the corpus. The Bag of Words algorithm returns:
u A vocabulary of words for the corpus.
u The frequency of these words.
For example, we have two sentences in the text document.
u “binary code is an efficient language.”
u “binary code is a code used in digital computers”.
Now, the whole sentence is segmented into tokens excluding the punctuation marks. Thus, we make a list of all
the tokens as:
‘Binary’, ‘code’, ‘is’, ‘an’, ‘efficient’, ‘language’, ‘a’, ‘used’, ‘in’, ‘digital’, ‘computers’
Now, Bag of Words algorithm create a vector by determining the frequency of words or tokens in the whole
corpus like:
158
158