
Page 286 - Ai Book - 10
P. 286
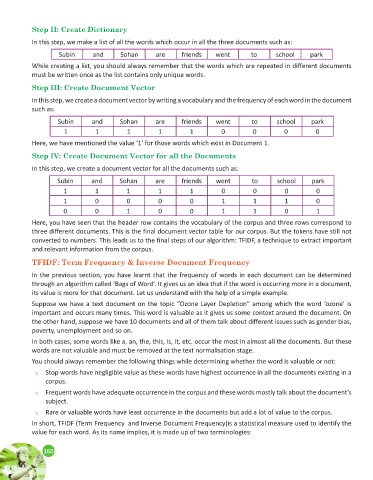
Step II: Create Dictionary
In this step, we make a list of all the words which occur in all the three documents such as:
Subin and Sohan are friends went to school park
While creating a list, you should always remember that the words which are repeated in different documents
must be written once as the list contains only unique words.
Step III: Create Document Vector
In this step, we create a document vector by writing a vocabulary and the frequency of each word in the document
such as:
Subin and Sohan are friends went to school park
1 1 1 1 1 0 0 0 0
Here, we have mentioned the value ‘1’ for those words which exist in Document 1.
Step IV: Create Document Vector for all the Documents
In this step, we create a document vector for all the documents such as:
Subin and Sohan are friends went to school park
1 1 1 1 1 0 0 0 0
1 0 0 0 0 1 1 1 0
0 0 1 0 0 1 1 0 1
Here, you have seen that the header row contains the vocabulary of the corpus and three rows correspond to
three different documents. This is the final document vector table for our corpus. But the tokens have still not
converted to numbers. This leads us to the final steps of our algorithm: TFIDF, a technique to extract important
and relevant information from the corpus.
TFIDF: Term Frequency & Inverse Document Frequency
In the previous section, you have learnt that the frequency of words in each document can be determined
through an algorithm called ‘Bags of Word’. It gives us an idea that if the word is occurring more in a document,
its value is more for that document. Let us understand with the help of a simple example.
Suppose we have a text document on the topic “Ozone Layer Depletion” among which the word ‘ozone’ is
important and occurs many times. This word is valuable as it gives us some context around the document. On
the other hand, suppose we have 10 documents and all of them talk about different issues such as gender bias,
poverty, unemployment and so on.
In both cases, some words like a, an, the, this, is, it, etc. occur the most in almost all the documents. But these
words are not valuable and must be removed at the text normalisation stage.
You should always remember the following things while determining whether the word is valuable or not:
u Stop words have negligible value as these words have highest occurrence in all the documents existing in a
corpus.
u Frequent words have adequate occurrence in the corpus and these words mostly talk about the document’s
subject.
u Rare or valuable words have least occurrence in the documents but add a lot of value to the corpus.
In short, TFIDF (Term Frequency and Inverse Document Frequency)is a statistical measure used to identify the
value for each word. As its name implies, it is made up of two terminologies:
160
160